
- SPSS����M(j��n)��A��^(q��)��
- SPSS��Ԫlogistic�ؚw�^(q��)�ֵ�ʹ�ü�
- ��SPSS���Ӌ(j��)����׃��
- ����\(y��n)��SPSS��(du��)��(sh��)��(j��)�M(j��n)���Y(ji��)
- SPSS����M(j��n)��Ƥ���d���P(gu��n)�ԅ^(q��)��
- SPSS����ΰ����@ʾ�c�����@ʾ��ժҪ��(b��o)��
- �����SPSS���M(j��n)�гɽM�O(sh��)Ӌ(j��)�ĸ���Y�ϵĿ���
- SPSS�е�OLAP����ʹ��Ԕ��(x��)�f��
- ���ʹ��SPSS�еĴ��a����(du��)���׃���c��(sh��)ֵ׃
- SPSS����M(j��n)���S�C(j��)���
- SPSS�ĽM��(n��i)���P(gu��n)ϵ��(sh��)�^(q��)�ֳ���(j��)����
- �����SPSS�а��b�ә�(qu��n)kappaӋ(j��)����
���]ϵ�y(t��ng)���d��� ����Windows10ϵ�y(t��ng)���d ����Windows7ϵ�y(t��ng)���d xpϵ�y(t��ng)���d ��X��˾W(w��ng)indows7 64λ�b�C(j��)�f�ܰ����d

SPSS������M(j��n)��Ѹ�پ�^(q��)��
�l(f��)���r(sh��)�g:2025-05-04 ����Դ:xp���dվ �g�[:
| SPSS��IBM��˾��Ʒ�����ṩ�˰��������Խy(t��ng)Ӌ(j��)���Ɣ��Խy(t��ng)Ӌ(j��)�����ӷ�������������ؚw�����ȶ�N�y(t��ng)Ӌ(j��)�������ܣ��������ı��������C(j��)���W(xu��)��(x��)�㷨����(sh��)��(j��)����ģ�͵ȡ�SPSS�Ľ����Ѻã����ڲ������܉����?g��u)Ĕ?sh��)��(j��)����ȡ���õĶ���ͷ������V����(y��ng)���ڽ������������t(y��)�W(xu��)���Ј�(ch��ng)���˿ڡ����U(xi��n)�ȶ���(g��)�о��I(l��ng)��Ҳ���ڮa(ch��n)Ʒ�|(zh��)�����ơ����n���������ճ��y(t��ng)Ӌ(j��)��(b��o)���ȡ� ����V�ܔ�(sh��)��(j��)��������A��һ�(sh��)��(j��)�y(t��ng)Ӌ(j��)�ͷ���ܛ����IBM SPSS Statistics����ȫ��Ĕ�(sh��)��(j��)���������������҂�Ҫ��B�������ľ�����е����پ������ һ���������� ������nj��о���(du��)����һ���Ę�(bi��o)��(zh��n)�M(j��n)�з�ķ�������Y(ji��)����ÿһ�M�Č�(du��)�����^�ߵ����ƶȣ��M�g�Č�(du��)������^��IJ�� �@������������ڌ�(du��)�ڔ�(sh��)��(j��)�ӱ��]���ض��ķ������(j��)����r��IBM SPSS Statistics��(hu��)ͨ�^��(du��)��(sh��)��(j��)���^����Ñ������^�����Ƶķ��
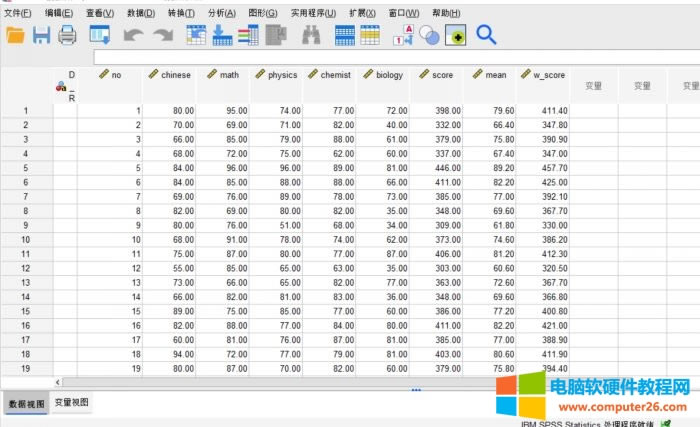
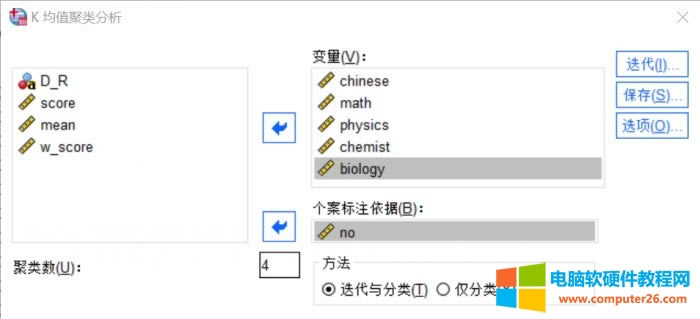
�D1������λ�� ���پ���Ǿ������һ�N��ʹ�õ��Ĺ�����“����”——“���”�е�“K-��ֵ���”�� ������������ 1.�ӱ���(sh��)��(j��)
�D2������λ�� �҂��@���x��Ĕ�(sh��)��(j��)�ӱ���һ���W(xu��)���ĸ�����ĩ�ɿ�(j��)��ʹ�ÿ��پ�������Է�������(g��)�W(xu��)���ɿ�(j��)�ֲ��IJ���ԡ� 2.׃���O(sh��)��
�D3������λ�� �҂����W(xu��)�������ІοƳɿ�(j��)�������׃�������뵽“׃��”�����У����W(xu��)���ľ�̖(h��o)׃�����뵽��(c��)��“��(g��)����(bi��o)ӛ����(j��)”���ڡ� ���(sh��)�O(sh��)�õ��Ƿ�Ĕ�(sh��)Ŀ���@��(g��)��Ҫ����(j��)��(sh��)��(j��)�ӱ������c(di��n)���O(sh��)�ã��҂��@���O(sh��)�Þ�4� ������Ѓ���������ͷ��ǰ���^���(f��)�s����(hu��)�ڷ����^���в����Ƅ�(d��ng)�����c(di��n)�����߄tʼ�Kʹ�ó�ʼ�����c(di��n)���҂��x�����еĵ�һ�N���������� 3.�������
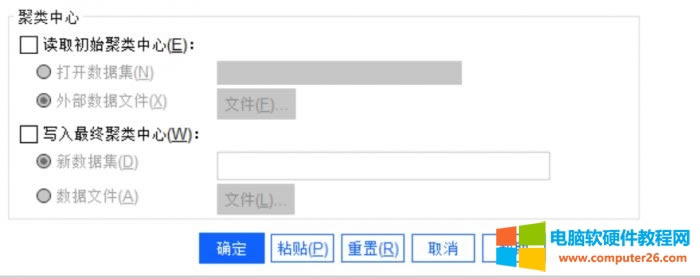
�D4��������� �Ñ������x����ⲿ�ļ���(sh��)��(j��)�ļ��Ќ�����xȡ������ģ����������҂���ʹ���@��(g��)���ܡ� 4.�����O(sh��)��
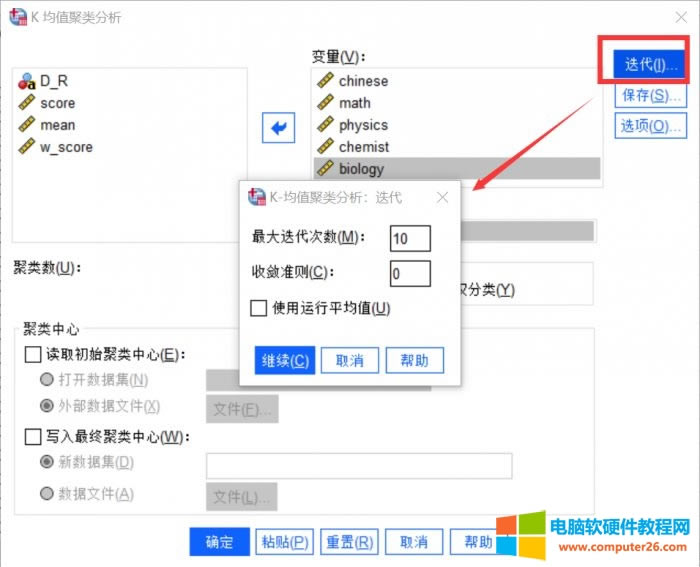
�D5�������O(sh��)�� �҂������O(sh��)�õ����ĽKֹ�l���������_(d��)�O(sh��)�������ֵ��ֹͣ����������ݔ��������Y(ji��)���� �Ք��Ԙ�(bi��o)��(zh��n)�O(sh��)�õ��������c(di��n)��׃�������xС�ڳ�ʼ�����c(di��n)�ı�����С���O(sh��)��ֵ�r(sh��)��Ҳ��(hu��)ֹͣ������ݔ���Y(ji��)���� ʹ���\(y��n)�о�ֵ��ʾÿ���^�y(c��)������Ӌ(j��)�������c(di��n)���@Щ�O(sh��)�ñ���Ĭ�J(r��n)���ɡ� 5.����
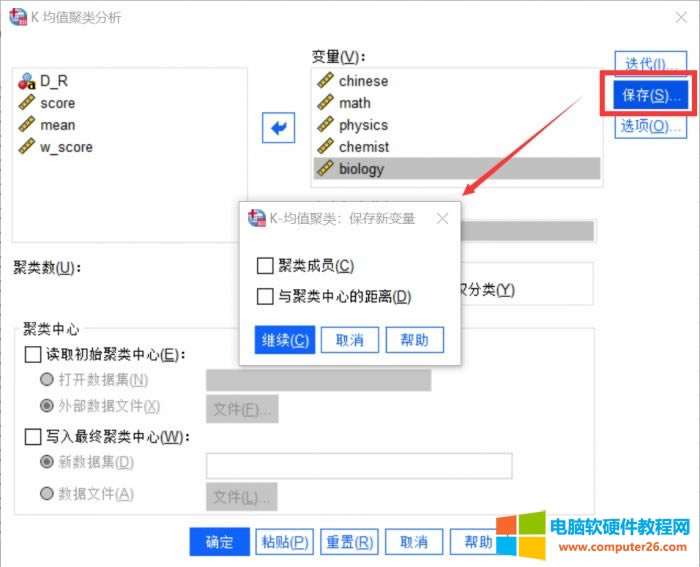
�D6��������׃�� �@���Á��O(sh��)�ñ�����ʽ�ģ����x“��ɆT”������SPSS�ķ�Y(ji��)�������x“�c������ĵľ��x”�������^�y(c��)ֵ������e�ĚW�Ͼ��x���҂������O(sh��)�á� 6.�x�(xi��ng)
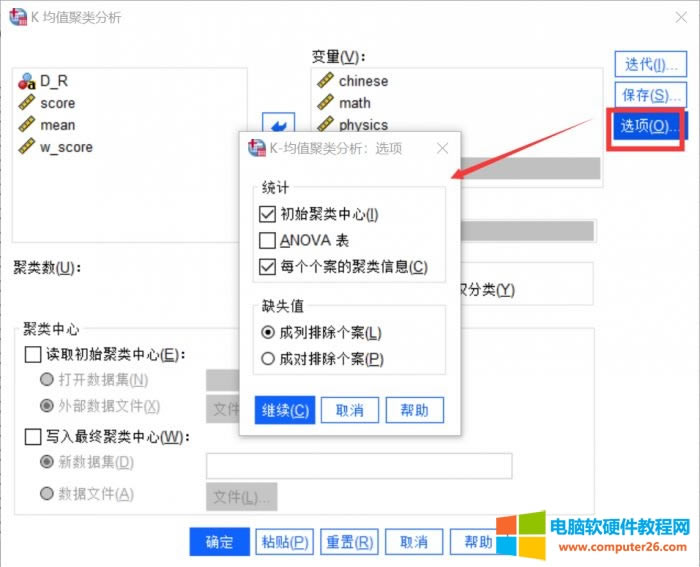
�D7���x�(xi��ng)�O(sh��)�� �@��(g��)��(du��)Ԓ���O(sh��)�õ���ݔ���Ľy(t��ng)Ӌ(j��)���͂�(g��)��ȱʧ̎�����������x“��ʼ�������”��“ÿ��(g��)��(g��)���ľ����Ϣ”�� 7.�Y(ji��)��ݔ��
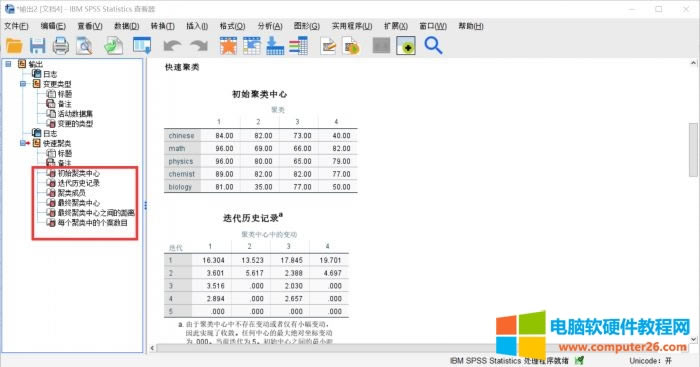
�D8����Y(ji��)�� ��ݔ����־�п��Կ������@Щ�W(xu��)������(j��)�����ĆοƳɿ�(j��)���ֳ������SPSSݔ���˶���(g��)��������ʼ������ġ������vʷӛ䛡���ɆT����K������ġ���K�������֮�g�ľ��x��ÿ��(g��)����еĂ�(g��)����(sh��)Ŀ������Ԕ��(x��)�����Ŷ��^�ߡ� ����С�Y(ji��) ʹ��IBM SPSS Statistics�M(j��n)�п��پ�ķ����Ͱ������������@ô�������@��һ��(g��)�^�鳣�õķ���������m�ó̶Ⱥܸߣ�ϣ�����Ԍ�(du��)������������� �������S����Ӱ푵Ĉ�(b��o)���s־��SPSS�o���˸߶ȵ��u(p��ng)�r(ji��)�� |
�������P(gu��n)�I�~�� SPSS�M(j��n)��Ѹ�پ�^(q��)��
��(d��ng)ǰԭ��朽ӣ�http://m.394287.com/soft2/soft-73237.html
���P(gu��n)����
Windowsϵ�y(t��ng)�̳̙�Ŀ
��̳�����
ϵ�y(t��ng)���T�̳�
1����\(y��n)��GHOST���bϵ�y(t��ng),��������\(y��n)���R���b�C(j��)
2ϵ�y(t��ng)֮�ҽ����A�T�Pӛ���A(y��)�bWindows10��w...
3ϵ�y(t��ng)֮��һ�IU�P���bwindows7ϵ�y(t��ng)�D��Ԕ��(x��)...
4Ů����ɶ���^��ã��m��Ů���\(y��n)�õ����^��_��
5���Ľ�����ΰ��bghostxpϵ�y(t��ng)
6�o�����(bi��o)�p�ĵĎNԭ�� �Լ�̎������
7Windows��������(j��)Win10ʧ����ʾ0x80...
8����(j��)Windows10 1607�汾�ľ��w�O(sh��)�÷�...
�����Tϵ�y(t��ng)������